

引言
据世界卫生组织估计,约15%的成年人(约7.66亿人)有一定程度的听力受损,并且随着世界人口的扩张和人口老龄化,这一数字还将持续上升。对更高级的智能助听设备的市场需求将会越来越大,智能助听设备的潜在市场不仅仅局限于听力受损人群,技术人员还可以将该技术应用到人机语音交互、复杂声场环境下的言语交流等方面。
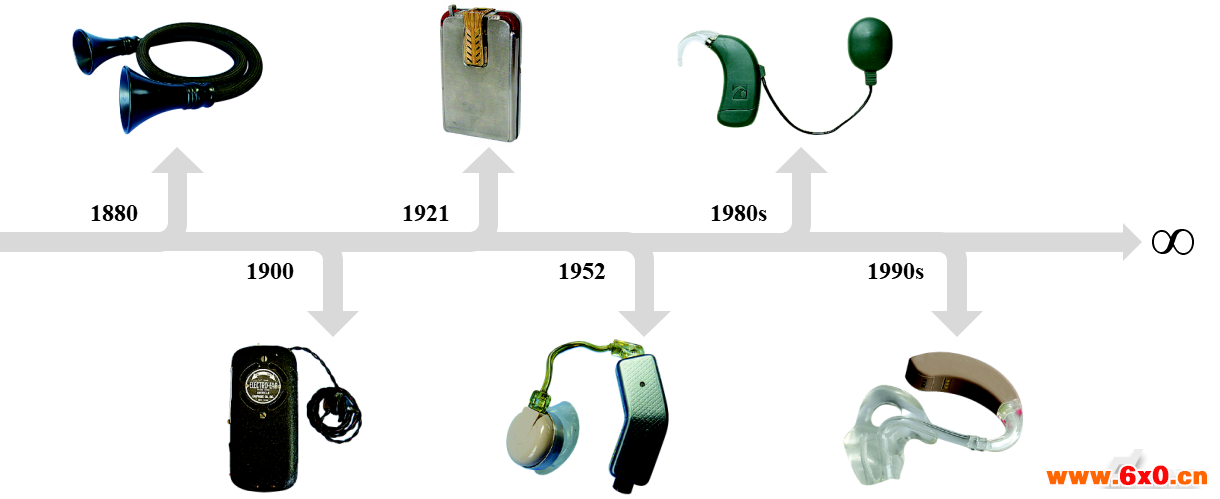
近150年以来,技术的不断变革在不断改善助听设备的性能。早期的通话管(1880年)完全依靠对声音的放大处理。到了1900年,第一台电助听设备诞生,它通过碳膜来放大声音。1921年,根据使用者听力损失类型的不同,出现使用真空管的助听设备。随着晶体管的出现,1952年第一台耳背式助听器诞生。20世纪80年代,针对听力受损严重患者,具有临床意义的电子人工耳蜗面世。上世纪90年代以来,将声波信号转换成数字信号的数字助听设备成为主流,如今的助听设备数字信号处理能力强大,对声音进行放大前还需做语音增强以去除背景噪声,以进一步提高助听设备的性能。
如何进行语音增强实现降噪成为目前提高助听设备性能的一大技术挑战。语音增强包括语音降噪、语音分离和语音去混响等,其目的都是改进语音质量,消除背景噪声。本调研文章介绍的语音增强主要为语音降噪技术,将主要介绍两种基于机器学习的方法,实现助听设备的智能化语音增强。
传统的语音降噪技术
长期以来,许多研究人员致力于研究语音降噪技术,这些降噪技术可以分为两类:多麦克风阵列和单麦克风框架。当目标语音和噪声在空间上可分离时,多麦克风阵列降噪方法的优势明显[1]。然而,在混响环境中,多麦克风的降噪方法的性能降低,并且它的应用通常局限于目标语音和噪声源空间可分离的声场[2]。因为附加的麦克风增加了设备费用和计算成本,因此,与多麦克风的降噪方法相比,单麦克风降噪方法更具经济优势。因此,研究人员提出了多种单麦克风降噪技术,例如INTEL[3-4]、对数最小均方误差(logMMSE)[5]、基于先验信噪比估计的维纳滤波器(Wiener)[6]、KLT[7-9]、ClearVoice[10]、基于信噪比的降噪方法[11]和广义最大后验频谱振幅[12]等。这些降噪方法大都是基于对语音和噪声信号的统计学分析而提出的[13]。另一种流行的传统降噪方法是使用端点检测器识别人说话的停顿间隙,将此指定为噪声,然后将其从带噪语音中“减去”获得降噪后的语音。这种降噪方法也被称为谱减法,但是它通常对噪声抑制太少或者消除太多噪声,以至于将目标语音也消除了,这也就带来了听起来有韵律感的音乐噪声,使得降噪后的语音质量下降。
Chen等人在2015年招募人工耳蜗植入者作为被试者,对几种单麦克风降噪方法效果进行了评估,发现大多数降噪方法在噪声条件下有效提高了人工耳蜗植入者的语音识别率。但是,这些方法在不同噪声条件下表现不一。传统的单麦克风降噪方法在稳定噪声条件下给人工耳蜗植入者的语音识别带来显著改善,但在具挑战性噪声条件下(例如当竞争信号是语音信号[14]或快变噪声[15]),仍然有很大的性能改善空间。基于机器学习的降噪方法在具挑战性的噪声条件下很好地弥补了传统降噪方法的短板。
基于噪声分类器+深度降噪自编码器的降噪方法
Lu等人2013年提出了一种基于深度降噪自编码器(DDAE)的降噪方法,该方法将降噪转换成非线性编码-解码任务,以此来映射噪声信号和干净语音信号之间的特征。Lu等人发现,针对常见噪声进行降噪,使用多种标准化客观评估,DDAE降噪方法的性能优于传统单麦克风降噪方法[16]。2017年,Lai等人评估了非匹配DDAE模型(即训练和测试阶段使用不同类型的噪声)对使用声码器生成的语音降噪效果。客观评估和主观听力测试的结果均表明,在非平稳噪声条件下,DDAE降噪方法处理后的语音可懂度高于传统降噪方法。非匹配的DDAE模型已经可以提供较好的降噪效果[17],但是只有当测试集和训练集噪声类型相同时(即匹配的DDAE模型),DDAE降噪效果才能达到最佳。因此,Lai等人于2018年提出了一种新的降噪方法,即采用额外的噪声分类器(以下简称NC)模块,来进一步提高基于DDAE降噪方法的性能。我们称之为NC+DDAE降噪方法。
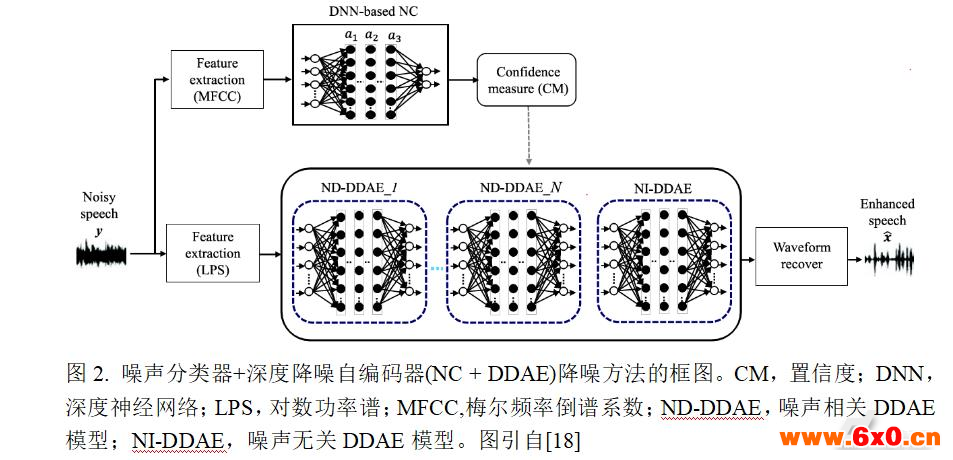
NC+DDAE降噪系统的细节框图[18]可参考图2。当给定带噪语音信号时,NC模块首先确定噪声类型并选择最合适的DDAE模型来执行降噪。在DDAE模块中,设计了多个噪声相关DDAE(noise-dependentDDAE,ND-DDAE)模型和一个与噪声无关的DDAE(noise-independentDDAE,NI-DDAE)模型。每个ND-DDAE都是根据某一特定类型的噪声进行训练的,而NI-DDAE则是针对多种噪声类型进行训练的。下面将分别介绍NC和DDAE模块。
基于深度神经网络的噪声分类器模块
NC模块是基于深度神经网络(deepneuralnetwork,DNN)模型构建的。DNN模型是在输入层和输出层之间具有许多隐藏层的前馈人工神经网络。如图2上半部分所示,使用梅尔频率倒谱系数(Mel-frequencycepstralcoefficients,MFCC)[19-20]作为NC模块的声学特征。MFCC广泛应用于各种声学模式分类任务,如音乐分类[21]和自动听诊[22]。MFCC特征提取过程包括六个步骤:(1)预加重:补偿在人类发声过程中被抑制的高频部分;(2)加窗:给定信号被分成一系列的帧;(3)快速傅立叶变换:获得每帧的频谱响应以进行频谱分析;(4)梅尔滤波:将梅尔滤波带的频率成分整合为单能量强度;(5)非线性变换:该变换取所有梅尔滤波带强度的对数形式;(6)离散余弦变换:将所有梅尔滤波带强度的对数转换成MFCC。研究表明,39维MFCC(13维原始MFCC+13维一阶MFCC+13维二阶MFCC)可以更精确地表征声学模式,从而产生更好的识别性能[23-24]。
在NC模块中,这里进一步采用置信度(ConfidenceMeasure,CM)[25]来评估识别结果的可靠性。CM分数表示我们可以相信识别结果的程度:分数越高表示对识别输出的置信度越高,反之亦然。计算完CM分数之后,定义一个阈值以对结果中的置信度分类。如前所述,NC模块的目标是确定噪声类型,然后根据噪声类型来选择最合适的DDAE模型来执行降噪。因此,如果所确定的噪声类型的CM评分高于阈值,则选择相应的ND-DDAE模型来执行降噪;另一方面,如果CM评分低于阈值,则直接使用NI-DDAE模型来执行降噪。
基于深度降噪自编码器的降噪模块
DDAE降噪模块的结构如图2下半部分所示。DDAE是一种有监督的降噪方法,基于DNN的架构,得到带噪语音信号和干净语音信号之间的映射函数。DDAE降噪方法有两个阶段:训练和测试阶段。在训练阶段,准备好一系列带噪和相应的干净语音信号对;在训练阶段,带噪-干净语音信号对首先转换为对数功率谱特征(LogPowerSpectra,LPS),LPS特征通常用在基于DNN降噪方法中[15,26]。对输入信号进行短时傅里叶分析,计算每个重叠加窗帧的离散傅里叶变换,从而获得LPS谱。
如图2所示,一共准备N个ND-DDAE模型(例如ND-DDAE_1至ND-DDAE_N)和一个NI-DDAE模型。一共N+1个模型都在训练阶段训练好。值得注意的是,每个ND-DDAE模型都是在某一特定噪声类型下训练,因此在这一特定噪声类型条件下,模型可以更准确地表征带噪语音信号转换到对应干净语音信号的特征。另外,NI-DDAE模型由多种类型的噪声训练,因此在特定噪声类型条件下降噪,它的表征能力不如ND-DDAE。但是,因为NI-DDAE模型由多种类型噪声训练,它对新出现的噪声类型降噪效果会较好。这里提出的NC+DDAE降噪方法可以总结如下:(1)当测试噪声类型被包含在训练集中,系统选择最恰当的ND-DDAE模型进行降噪(即匹配的DDAE模型);(2)当测试噪声不被包含在训练集中,NI-DDAE模型用来降噪(即非匹配的DDAE模型),它对不同类型噪声的泛化能力较好。
效果评测
为了测试NC+DDAE降噪方法的效果,研究采用归一化协方差度量(NormalizedCovarianceMeasure,NCM)[27]来客观评估降噪后的语音的可懂度,并招募了9名说普通话的人工耳植入者进行临床听力测试,使用词正确率(WordCorrectRate,WCR)[17,28-31]作为评估指标。测试过程采用双人交流噪声和建筑手提钻噪声,信噪比等级分别设置为0和5dB。NCM评分和WCR评分都表明,NC+DDAE降噪方法相比于传统单麦克风降噪方法和DDAE降噪方法,降噪效果有显著性提升。
与传统的降噪技术相比,NC+DDAE降噪方法可以被视为只需数据的有监督学习方法。这种降噪方法学习从带噪语音信号到干净语音信号的映射函数,而不会强加任何假设。再基于NC+DDAE模型的映射函数,不使用任何噪声估计算法,将带噪语音直接转换为干净的语音。因此,即使在处理困难的,竞争性噪声或信噪比0dB时,NC+DDAE降噪后的语音可懂度也比传统降噪方法高。
基于深度神经网络+理想二值掩蔽的降噪方法
1990年,来自加拿大蒙特利尔麦吉尔大学的心理学家AlbertBregman,提出人类听觉系统将声音分成不同的声音流,例如,几个朋友一边聊天一边放着音乐,这就构成了所谓的听觉场景。听觉场景中每个声音流的音调、响度和方向都是不同的。如果两个声音在同一时间共享了同一频段,响度高的声音流压倒响度较低的,这就是听觉掩蔽原理,譬如,屋外的雨打在窗户上发出“滴答滴答”的声音,人可能就不会注意到屋内挂钟的滴答声。
基于上述提到的原理,来自美国俄亥俄州立大学的WangDeliang提出了理想二值掩蔽方法[32],在一个特定频段内的一个特定短暂间隔(或时频单元),理想二值掩蔽滤波器分析带噪语音的每个时频单元,并将每个时频单元标记为“0”或者“1”,如果目标语音强于噪声,标记为1,反之标记为0。然后滤波器抛弃标记为0的单元,利用标记为1的时频单元重建语音。理想二值掩蔽极大改善了听力障碍者的语音理解能力,但是这里的理想二值掩蔽是停留在实验室层面的,实验设计将语音和噪声混合,滤波器是知道什么时候目标语音比噪声响度大的,因此称之为理想的。一个真正实用的二值掩蔽滤波器,需要完全独立地实时地将声音从背景噪声中分离出来。因此Wang等人尝试了将深度神经网络结合理想二值掩蔽的降噪方法,以实现机器独立地学习区分目标语音和背景噪声。
效果评测
为了测试深度神经网络+理想二值掩蔽方法的降噪效果,研究人员招募了12位听力受损者和12位听力正常者进行测试,被试者通过耳机听语音样本。样本是成对的:首先是原始带噪音频,然后是基于深层神经网络的程序处理后的音频。使用两种噪音进行测试,即平稳的“嗡嗡嗡”噪声和许多人同时说话的噪声。许多人同时说话噪声是创造了嘈杂的噪声背景,加入四名男性和四名女性说话语句,模仿鸡尾酒会场景。
两组被试者测试结果表明,通过神经网络对带噪语音进行降噪,语音信号的可懂度都有了很大的提高。在多人同时说话噪声条件下,听力障碍者只能理解原始带噪语音29%的内容,但对于处理后的音频,他们理解的内容达到了84%。更有结果从10%提高到了90%。在稳定噪声条件下,类似的改善也很明显,被试者的理解程度从36%提高到了为82%。
经过上述方法降噪后,正常听力者的表现也有所提升,这意味着此研究的应用前景比预期的要大得多。稳定噪声条件下,听力正常者理解程度从37%提升到了80%。在多人同时说话噪声条件下,他们的表现从40%提高到了78%。
有趣的是,研究人员发现,使用上述降噪方法后,听力障碍者的表现甚至会超过正常听力者,这意味着基于深度神经网络的方法,有望解决迄今为止研究人员花费无数精力的“鸡尾酒会效应”问题。
未来展望
现实生活场景中,噪声是多样化的,因此应用到实际场景中,无论是噪声分类器+深度降噪自编码器降噪方法,还是深度神经网络+理想二值掩蔽降噪方法,都需要学会快速滤除同时出现的多种类型噪声,包括训练集中未出现过的新噪声。研究人员通过增加训练集噪声的种类和数量,例如,Wang等人将训练数据中噪声类型提高了10000种,不断优化改进训练后的模型,以实现基于机器学习语音增强的现实应用意义。
另外,计算复杂度目前是基于DNN的降噪方法在助听设备中应用的关键问题。由于其多层结构,DNN模型在运行时需要大量内存和高计算成本。因此,保持其性能的同时,减少在线计算量,以此来简化DNN模型的架构,这样的要求是非常苛刻的。最近,研究人员提出了许多方法来制备基于DNN的高度可重构且节能的处理器,用来实施各类模式分类和回归任务[33-39]。同时,研究人员也在努力解决高计算成本的问题。例如,蒸馏方法[40]将复杂模型转换成到更适合部署的简化模型。另一个著名的方法是在基于深度学习的模型中,对参数进行二进制化处理以减少内存大小和访问量[41]。随着深度学习算法和硬件的快速发展,上述提到的降噪方法可以在不久的将来在助听设备中实现应用。此外,已有多个系统可以将助听设备与智能手机,电视机或MP3播放器等其他设备集成。这些设备可以为助听设备提供更优越的计算和存储能力,因此,这也可以很好地解决基于机器学习降噪方法的高计算成本问题。目前,诸如美国明尼苏达州的Starkey听力技术公司,正致力于将机器学习技术与实际助听设备结合。
机器学习和神经网络的发展很大程度地推动了各行业的智能化发展,相信在不久的将来,基于机器学习实现助听设备的智能语音增强技术将得以应用,为听力障碍者乃至整个人类带来福音。












 QQ交流群
QQ交流群

