

引言
行人检测任务的目标是在图像中检测行人并确定行人的位置。随着人工智能技术的发展,越来越多的研究人员关注这项任务并且做了很多相关的研究工作。准确的行人检测方法可以应用于很多领域,例如智能辅助驾驶,智能视频监控和智能机器人等。
近年来,区域卷积神经网络(R-CNN)模型被广泛应用于通用类物体检测任务。有相关文献提出了一种快速区域卷积神经网络(FastR-CNN)模型,在21类的物体检测任务中取得了显著的效果。这种模型首先使用候选区域框方法SelectiveSearch去预测物体可能存在的位置,然后再使用卷积神经网络对候选区域框进行进一步的精细分类和定位。受这种模型在通用类检测中的启发,我们试图将这种方法应用于行人检测。但是SelectiveSearch方法不是针对单一类的候选框提取方法,它会预测所有种类物体的可能位置,包括车辆,建筑等。因此生成的候选区域框存在很多的冗余,降低训练的分类器的质量。同时冗余的候选区域框会消耗较多的计算资源,降低卷积神经网络的训练和测试的速度。在行人检测中,只对行人类别生成候选区域框,并使用这种候选框训练和测试卷积神经网络,理论上可以取得很好的检测效果。
候选区域框提取在一定程度可以看作对物体的粗糙检测。我们可以对图像提取特征,并训练一个判别行人的简单分类器,使用分类器去生成候选区域框。这样就可以实现只针对行人类别提取候选区域框的目的。基于这个思想,本文提出了一种适用于行人检测的候选框提取方法。我们将这种候选框提取方法与卷积神经网络模型结合起来,并应用于行人检测。这种检测方法主要分为两步:1)使用候选框提取方法为每张图像生成候选区域框;2)将图像和它的候选区域框输入到卷积神经网络中。网络包含两个输出层。一个输出行人类别的概率估计,另一个输出四个实数表示行人边界框的位置。
本文的模型和其他行人检测方法相比取得了很好的检测效果。在INRIA,PKU和ETH数据集上分别实现了14.1%,15.3%和45.6%的漏检率。实验结果表明,在行人检测任务中我们的候选框提取方法要比SelectiveSearch更有效。同时,我们的方法去除了冗余的候选区域框,提高了卷积神经网络训练和测试的速度。
背景
1.现有行人检测算法的分类
现有的行人检测算法通常会被分为两类。第一类称为传统算法,这类方法从图像中提取手工设计特征并训练一个支持向量机(SVM)或增强(boosting)作为分类器。这些手工设计特征包括哈尔,梯度直方图和局部二值模式等,在行人检测表现出很好的性能。DPM在检测中考虑了局部的区域特征以及区域间的形变。有相关文献将上下文信息加入到模型中。另外,聚合通道特征将梯度直方图和LUV颜色空间特征融合到一起用于行人检测。文献提出了一种有效的特征变换方法去除了局部特征间的关联。
另一类行人检测方法是采样深度模型。深度模型可以从原图像中学习特征,极大地提高了行人检测算法的性能。从行人的不同身体部门学习特征来处理行人间的遮挡问题,卷积网络方法采用卷积稀疏编码无监督地预训练卷积神经网络,通过语义的特征优化行人检测效果。
2.候选框提取方法
由于物体可能是任意尺寸并且可能出现在图像的任一位置,因此需要搜索整幅图像来完成分类和定位。滑动窗口方法可以获得所有可能的物体位置,但是计算复杂度很高。最近,研究人员提出了其他几种候选框提取方法,例如selectivesearch,bing和edgeboxes。Selectivesearch通过分割和相似度计算的方式提取候选区域框,区域框的质量较好但是速度很慢。Bing使用正则梯度信息和二分操作生成候选区域框,速度较快但是质量很差。Edgeboxes是在质量和速度之间折中的一种算法。
这类方法生成的候选区域框包含了所有的种类,适用于通用类的检测,但无法完成单一类的候选框提取。冗余的候选区域框会降低卷积神经网络的性能,并消耗更多的计算资源。行人检测问题只需要针对行人类别生成候选区域框而无需其它物体的冗余信息,本文实现了一种基于行人检测算法的候选区域框提取方法。我们将这种优化的候选区域框提取方法和卷积神经网络结合起来,并将其应用于行人检测。
提出的方法
1.方法概述
本文所提出的方法包括两部分。第一部分是候选区域框的提取,第二部分是卷积神经网络模型。其中候选框提取方法采用聚合通道特征(ACF),卷积神经网络模型基于文献中的深度网络结构。网络的输入是原始的图像和候选区域框。模型首先通过卷积和池化提取图像的卷积特征,经由兴趣区域池化(RoI)层将候选区域框的卷积特征映射为固定长度的特征向量并被传入全连接层。全连接层后面有两个平行的输出层,输出行人检测框的置信分数和坐标。
2.候选区域框提取
该候选区域框算法从图像中提取10个通道的手工设计特征并训练一个AdaBoost分类器。通道特征包括归一化的梯度幅值,梯度方向(6bins)和LUV颜色通道。算法通过计算不同尺度下的通道特征构建特征金字塔。不同尺寸下的特征不是直接计算,而是通过相邻尺寸的特征近似计算获得,其详细过程如下文所述。
对于图像I,设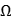 为任意低层次旋转不变特征计算方法,图像的一个通道计算方法为
为任意低层次旋转不变特征计算方法,图像的一个通道计算方法为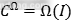 。通道C是像素级别的特征,C中每个像素都是从对应图像I的图像块计算而来。设
。通道C是像素级别的特征,C中每个像素都是从对应图像I的图像块计算而来。设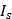 表示图像I在s尺寸下的重采样,
表示图像I在s尺寸下的重采样,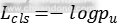 ,R表示采样函数。当计算多尺寸图像特征时,首先将图像I在尺寸s下重采样,之后通过近似计算得到
,R表示采样函数。当计算多尺寸图像特征时,首先将图像I在尺寸s下重采样,之后通过近似计算得到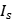 的通道特征。近似计算方法如下:
的通道特征。近似计算方法如下:
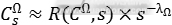
 是不同尺寸间的变换因子,每种通道。征类型
是不同尺寸间的变换因子,每种通道。征类型 对应一个
对应一个 。通用的特征金字塔方法通常是在每一个尺寸计算
。通用的特征金字塔方法通常是在每一个尺寸计算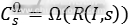 。这种近似计算的方法在框的提取速度。在候选区域框提取过程中,本文首先对图像提取10通道的特征,然后使用近似计算得到不同图像尺寸下的特征构建特征金字塔。最后训练了一个由2048个深度为2的分类树组成的Adaboost分类器生成候选区域框。为了获得足够的候选区域框,我们降低了检测的阈值。
。这种近似计算的方法在框的提取速度。在候选区域框提取过程中,本文首先对图像提取10通道的特征,然后使用近似计算得到不同图像尺寸下的特征构建特征金字塔。最后训练了一个由2048个深度为2的分类树组成的Adaboost分类器生成候选区域框。为了获得足够的候选区域框,我们降低了检测的阈值。
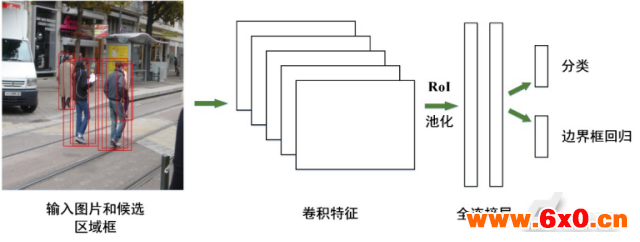
图1.卷积神经网络结构
网络结构
在这一部分,我们首先介绍采用的深度网络模型的结构,然后说明模型的损失函数。
本文的网络结构如图1所示。网络包含5个卷积层。每个卷积层分别有96,256,384,384和256个核函数。采用线性整流函数(ReLU)作为网络的激活函数。每个卷积层后面连接了一个空间最大池化层。网络可以输入任意尺寸的图像。经过卷积和池化,得到图像的卷积特征。在卷积特征传入全连接层之前,兴趣区域池化层会将卷积特征映射为固定长度的特征向量。分别使用标准差为0.01和0.001的高斯分布初始化用于分类和边界框回归的全连接层权重(weights)。偏置(bias)初始化为0。网络的每一层权重的学习率为0.001,偏置的学习率为0.002。
全连接层后面连接了两个平行输出层。第一个输出层输出在行人和背景类上的概率值,用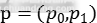 表示。其中
表示。其中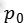 和
和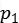 分别表示物体是背景和行人的概率值。通常,p通过在全连接层的两个输出加上softmax计算得到。第二个输出层是在行人类上的边界框回归补偿,使用
分别表示物体是背景和行人的概率值。通常,p通过在全连接层的两个输出加上softmax计算得到。第二个输出层是在行人类上的边界框回归补偿,使用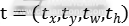 表示。每个训练的候选区域框都有一个类别标定u和边界框目标v。我们使用了多任务损失函数L同时训练分类和边界框回归:
表示。每个训练的候选区域框都有一个类别标定u和边界框目标v。我们使用了多任务损失函数L同时训练分类和边界框回归:
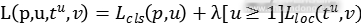
其中是类别u的对数损失函数。第二个任务的损失函数是在类别u的边界框上定义的,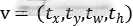 。当
。当 时,艾弗森括号指示函数
时,艾弗森括号指示函数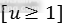 值为1,其他值为0。按照惯例,通用背景类被标记为u=0。由于背景类的候选区域框没有特定的标注,此时在损失函数中就将背景类的
值为1,其他值为0。按照惯例,通用背景类被标记为u=0。由于背景类的候选区域框没有特定的标注,此时在损失函数中就将背景类的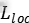 忽略不计。对于行人类的边界回归,使用如下损失函数:
忽略不计。对于行人类的边界回归,使用如下损失函数:
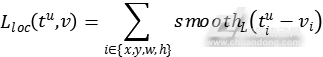
其中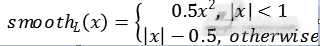 参数
参数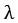 控制两个任务损失之间的平衡。标注的回归目标v被归一化为零均值和单位方差。在所有的实验中,本文都设置
控制两个任务损失之间的平衡。标注的回归目标v被归一化为零均值和单位方差。在所有的实验中,本文都设置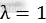 。本文使用随机梯度下降的方法最小化损失函数。
。本文使用随机梯度下降的方法最小化损失函数。
结束语
本文提出了一种单一类候选框提取方法与卷积神经网络结合的模型。该候选框提取算法从图像中提取手工设计特征,并训练AdaBoost分类器。本文所提出的方法不同于通用的候选框提取方法,可以只为行人类别生成候选区域框。本文还阐述了候选框提取算法的具体细节以及网络的结构。实验的结果表明,本文的方法提高了候选框提取的质量,在行人检测上取得了很好的效果,同时缩短了网络训练和测试的时间。








 QQ交流群
QQ交流群

